Create an API Key
Since you'll be using
curl to send a request to the Speech API, you'll need to generate an API key to pass in your request URL.
To create an API key, navigate to:
APIs & services > Credentials:
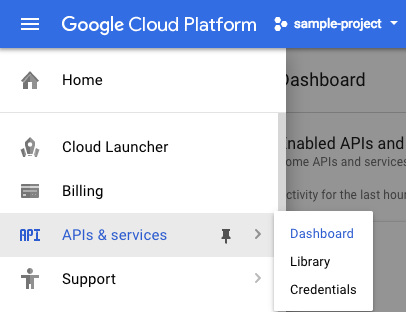
Then click Create credentials:
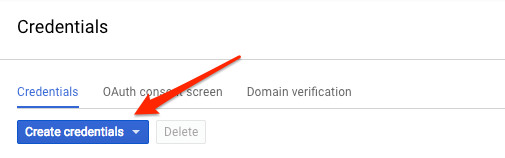
In the drop down menu, select API key:
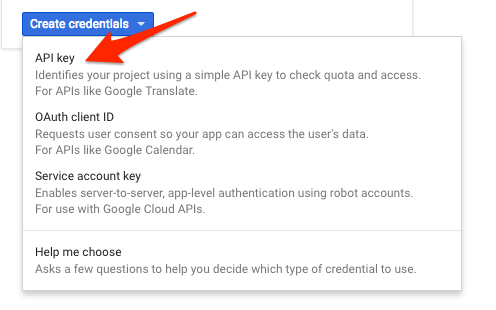
Next, copy the key you just generated. Click Close.
Now save your key to an environment variable to avoid having to insert the value of your API key in each request.
In Cloud Shell run the following, replacing
<your_api_key> with the key you just copied:export API_KEY=<YOUR_API_KEY>
Create your Speech API request
Build your request to the Speech API in a
request.json file in Cloud Shell:touch request.json
Open the file using your preferred command line editor (
nano, vim, emacs) or gcloud. Add the following to your request.json file, using the uri value of the sample raw audio file:{
"config": {
"encoding":"FLAC",
"languageCode": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}
The request body has a
config and audio object.
In
config, you tell the Speech API how to process the request:- The
encodingparameter tells the API which type of audio encoding you're using while the file is being sent to the API.FLACis the encoding type for .raw files (here is documentation for encoding types for more details). languageCodewill default to English if left out of the request.
There are other parameters you can add to your
config object, but encoding is the only required one.
In the
audio object, you pass the API the uri of the audio file which is stored in Cloud Storage for this lab.
Now you're ready to call the Speech API!
Call the Speech API
Pass your request body, along with the API key environment variable, to the Speech API with the following
curl command (all in one single command line):curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json \
"https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}"
Your response should look something like this:
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}
The
transcript value will return the Speech API's text transcription of your audio file, and the confidence value indicates how sure the API is that it has accurately transcribed your audio.
Notice that you called the
syncrecognize method in our request above. The Speech API supports both synchronous and asynchronous speech to text transcription. In this example a complete audio file was used, but you can also use the syncrecognize method to perform streaming speech to text transcription while the user is still speaking.Speech to text transcription in different languages
Are you multilingual? The Speech API supports speech to text transcription in over 100 languages! You can change the
language_code parameter in request.json. You can find a list of supported languages here.
Let’s try a French audio file (listen to it here if you’d like a preview).
Edit your
request.json and change the content to the following: {
"config": {
"encoding":"FLAC",
"languageCode": "fr"
},
"audio": {
"uri":"gs://speech-language-samples/fr-sample.flac"
}
}
Now call the Speech API by running the
curl command again.
You should see the following response:
{
"results": [
{
"alternatives": [
{
"transcript": "maître corbeau sur un arbre perché tenait en son bec un fromage",
"confidence": 0.9710122
}
]
}
]
}
This is a sentence from a popular French children’s tale. If you’ve got audio files in another language, you can try adding them to Cloud Storage and changing the
languageCode parameter in your request.
沒有留言:
張貼留言