Create an API Key
Since you'll be using
curl to send a request to the Vision API, you'll need to generate an API key to pass in your request URL.
To create an API key, navigate to APIs & services > Credentials in your Cloud console:
Click on the Create credentials button.
In the drop-down menu, select API key.
Next, copy the key you just generated and save it to an environment variable to avoid having to insert the value of your API key in each request. Run the following, replacing
<your_api_key> with the key you just copied:export API_KEY=<YOUR_API_KEY>
Upload an Image to a Cloud Storage bucket
Creating a Cloud Storage bucket
There are two ways to send an image to the Vision API for image detection: by sending the API a base64 encoded image string, or passing it the URL of a file stored in Google Cloud Storage. We'll be using a Cloud Storage URL. The first step is to create a Google Cloud Storage bucket to store our images.
Navigate to Navigation menu > Storage in the Cloud console for your project, then click Create bucket.
Give your bucket a unique name and click Create.
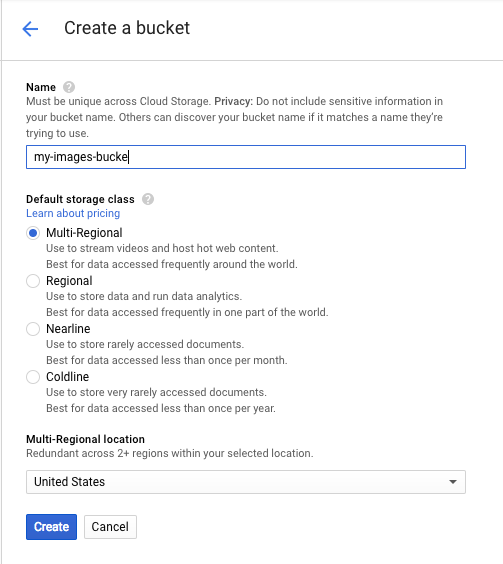
Upload an image to your bucket
Right click on the following image of donuts, then click Save image as and save it to your computer as donuts.png.

Go to the bucket you just created and click Upload files. Then select donuts.png.
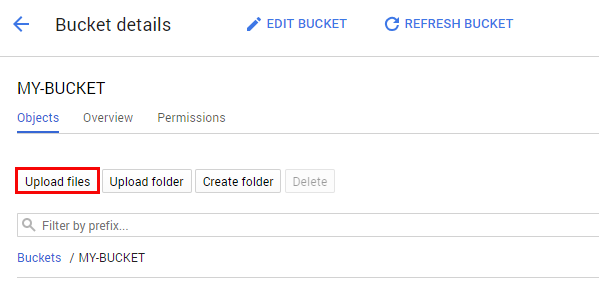
You should see the file in your bucket.
Next, click on the 3 dots for your image and select Edit Permissions.
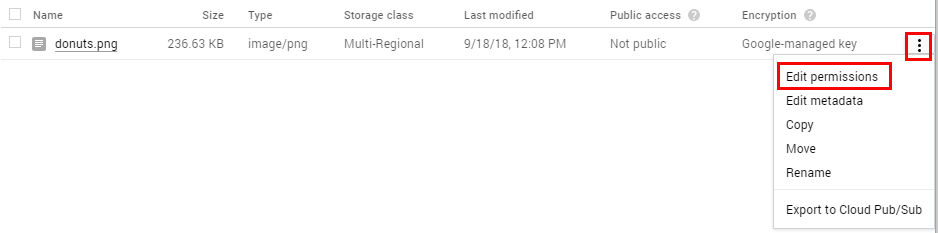
Click Add item then enter the followoing:
Entity: Group
Name: allUsers
Access: Reader
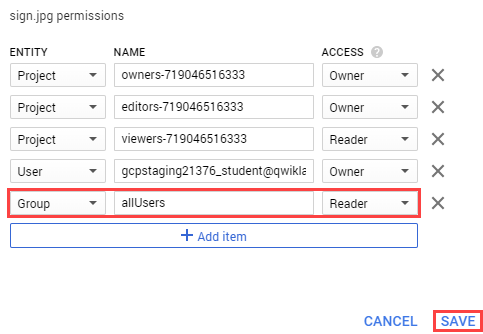
Then click Save.
Now that you have the file in your bucket, you're ready to create a Vision API request, passing it the URL of this donuts picture.
Create your Vision API request
Now you'll create a
request.json file in the Cloud Shell environment.
Using
gcloud (by clicking the pencil icon in the Cloud Shell ribbon),
or your preferred command line editor (
nano, vim, or emacs), create a request.json file by running the following:{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}
Save the file.
Label Detection
The first Cloud Vision API feature you'll try out is label detection. This method will return a list of labels (words) of what's in your image.
Call the Vision API with
curl:curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
Your response should look something like the following:
{
"labelAnnotations": [
{
"mid": "/m/02wbm",
"description": "Food",
"score": 94
},
{
"mid": "/m/0ggjl84",
"description": "Baked Goods",
"score": 90
},
{
"mid": "/m/02q08p0",
"description": "Dish",
"score": 85
},
{
"mid": "/m/0270h",
"description": "Dessert",
"score": 83
},
{
"mid": "/m/0bp3f6m",
"description": "Fried Food",
"score": 75
},
{
"mid": "/m/01wydv",
"description": "Beignet",
"score": 67
},
{
"mid": "/m/0pqdc",
"description": "Hors D Oeuvre",
"score": 54
}
]
}
The API was able to identify the specific type of donuts these are, beignets. Cool! For each label the Vision API found, it returns a:
descriptionwith the name of the item.score, a number from 0 - 100 indicating how confident it is that the description matches what's in the image.midvalue that maps to the item'smidin Google's Knowledge Graph. You can use themidwhen calling the Knowledge Graph API to get more information on the item.
Web Detection
In addition to getting labels on what's in your image, the Vision API can also search the Internet for additional details on your image. Through the API's webDetection method, you get a lot of interesting data back:
- A list of entities found in your image, based on content from pages with similar images
- URLs of exact and partial matching images found across the web, along with the URLs of those pages
- URLs of similar images, like doing a reverse image search
To try out web detection, use the same image of beignets and change one line in the
request.json file (you can also venture out into the unknown and use an entirely different image).
Under the features list, change type from
LABEL_DETECTION to WEB_DETECTION. The request.json should now look like this:{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}
Save the file.
To send it to the Vision API, use the same
curl command as before (just press the up arrow in Cloud Shell):curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
Let's dive into the response, starting with
webEntities. Here are some of the entities this image returned: "webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
This image has been used in many presentations on Cloud ML APIs, which is why the API found the entities "Machine learning" and "Google Cloud Platform".
If you inpsect the URLs under
fullMatchingImages, partialMatchingImages, and pagesWithMatchingImages, you'll notice that many of the URLs point to this lab site (super meta!).
Let's say you wanted to find other images of beignets, but not the exact same images. That's where the
visuallySimilarImages part of the API response comes in handy. Here are a few of the visually similar images it found:"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]
You can navigate to those URLs to see the similar images:




And now you probably really want a beignet(sorry)! This is similar to searching by an image on Google Images.
With Cloud Vision you can access this functionality with an easy to use REST API and integrate it into your applications.
Face and Landmark Detection
Next explore the face and landmark detection methods of the Vision API.
- The face detection method returns data on faces found in an image, including the emotions of the faces and their location in the image.
- Landmark detection can identify common (and obscure) landmarks. It returns the name of the landmark, its latitude and longitude coordinates, and the location of where the landmark was identified in an image.
Upload a new image
To use these two methods, you'll upload a new image with faces and landmarks to the Cloud Storage bucket.
Right click on the following image, then click Save image as and save it to your computer as selfie.png.

Now upload it to your Cloud Storage bucket the same way you did before, and make it public.
Updating request file
Next, update your
request.json file with the following, which includes the URL of the new image, and uses face and landmark detection instead of label detection. Be sure to replace my-bucket-name with the name of your Cloud Storage bucket:{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}
Save the file.
Calling the Vision API and parsing the response
Now you're ready to call the Vision API using the same
curl command you used above:curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
Take a look at the
faceAnnotations object in the response. You'll notice the API returns an object for each face found in the image - in this case, three. Here's a clipped version of the response:{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}
boundingPolygives you the x,y coordinates around the face in the image.fdBoundingPolyis a smaller box thanboundingPoly, focusing on the skin part of the face.landmarksis an array of objects for each facial feature, some you may not have even known about. This tells us the type of landmark, along with the 3D position of that feature (x,y,z coordinates) where the z coordinate is the depth. The remaining values gives you more details on the face, including the likelihood of joy, sorrow, anger, and surprise.
The response you're reading is for the person standing furthest back in the image - you can see he's making kind of a silly face which explains the
joyLikelihood of POSSIBLE.
Next look at the
landmarkAnnotations part of the response:"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]
Here, the Vision API was able to tell that this picture was taken in Petra - this is pretty impressive given the visual clues in this image are minimal. The values in this response should look similar to the
labelAnnotations response above:- the
midof the landmark - it's name (
description) - a confidence
score - The
boundingPolyshows the region in the image where the landmark was identified. - The
locationskey tells us the latitude longitude coordinates of this landmark.
Explore other Vision API methods
You've looked at the Vision API's label, face, and landmark detection methods, but there are three others you haven't explored. Dive into the docs to learn about the other three:
- Logo detection: identify common logos and their location in an image.
- Safe search detection: determine whether or not an image contains explicit content. This is useful for any application with user-generated content. You can filter images based on four factors: adult, medical, violent, and spoof content.
- Text detection: run OCR to extract text from images. This method can even identify the language of text present in an image.
沒有留言:
張貼留言